
The Cloud and The Internet of Things
2020年5月27日
アメリカ訴訟弁護士が語る ~激動期にはスピードが大事は本当? 寝て待つ「漁夫の利」作戦~
2020年5月28日
FRONTEOの2つのAIエンジンは、テキストデータから曖昧な感覚や行動の意味、予兆を見える化し、“判断”に導く


・ なぜ「ブラックボックス」と言われるか?
・ FRONTEOのAIエンジンが「見える化」するアプローチ
・ 「幸せ」のような曖昧な感覚をAIで見つけるには? (近日公開)
・ FRONTEOが見つけてきた「○○○○○○」 (近日公開)
AIを使ったサービスの利用が世の中に広がってきています。個人では、スマートフォンで撮った顔写真をキレイにしたり、スマートスピーカーで商品を注文したり、パソコンで外国語の文章を日本語に翻訳したり、といった利用が暮らしの中で定着しています。
では企業はどうでしょう? 企業向けにもAIを活用したサービスが提供されていますが
実際に業務に導入している企業は
14.1%
(出典:総務省・ICR・JCER「AI・IoTの取組みに関する調査」(2019年3月発表))
先駆的な利用は
わずか 7.6%
(出典:IDC Japan「国内ユーザー企業のAI活用の取り組みに関する成熟度を発表」(2020年3月発表))
という調査結果も出ています。企業のAIの利用が進んでいないのは、業務内容や利用環境に合わせたカスタマイズが難しい、使えるデータが十分に揃わない、概念実証(PoC)で効果があっても、採算が合わないといった理由が挙げられますが、最近、目にするものの中にAIの「ブラックボックス」問題があります。
2012年頃から始まったと言われる第3次AIブームで、技術的なブレイクスルーとなったものに、ディープラーニング(深層学習)という手法があります。(図1)]
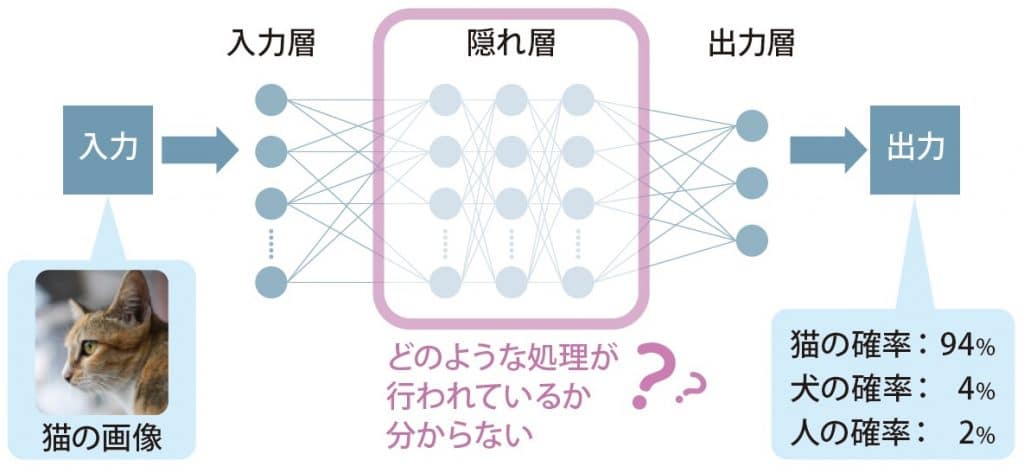

図1. ディープラーニングの例
ディープラーニングは、脳の神経回路、ニューロンとシナプスの働きを数学的に模倣したニューラルネットワークがベースとなっています。入力層と出力層の間に、隠れ層を多数挟んで計算することにより、複雑な学習をすることができ、画像や映像の解析、翻訳など多方面で成果を上げています。一方、解析には万単位のデータや高性能の機材が必要となるという課題に加え、隠れ層の中で「AIがどういう特徴を捉えたか分からない」点が「ブラックボックス」と言われています。
AIは、与えられたデータから何らかの特徴を見つけ出し、処理を行った結果を示していますが、先程のディープラーニングの例では、ある実験で正しい結果が出たとしても、処理をおこなう判断のプロセスや根拠が分からないため、他の未知のケースで同じように使えるかどうか判断が難しいとされています。
現在、ディープラーニングを使ったモデルを提供している各社は、データが結果に与えた影響を定量化したり、推定結果の理由や根拠を示したり、仮説を抽出するなど、人が確認できることでAIを安心して活用できるように開発が進んでいます。
では、FRONTEOは、AIでの解析にあたり「ブラックボックス」にどういうアプローチをとっているでしょうか?
FRONTEOのAIエンジンは、KIBIT(キビット)が2012年から、Concept Encoder(コンセプト・エンコーダー)が2018年から稼働しています。これらを用いて日常にある言葉、文章や文書といった自然言語を解析することで、この世の中の「見つけたいもの」を発見するプロセス、ソリューションを提供し続けています。ディープラーニングとは異なる独自のアプローチで、数件から数十件の少ないデータからでも学習ができ、処理が軽いことが特徴です。
FRONTEOは、「ブラックボックス」にならないよう、AIによる解析のプロセスや結果を「見える化」することによって、人に説明したり、判断が可能になる「説明可能性」を高めることを重視しています。
FRONTEOのAIエンジンKIBITでは、言語解析において、2016年よりスコアリング(点数化)への影響度が高い箇所(句読点や改行コードで区切られた単位)を重要箇所としてハイライトで表示することに取り組み、2019年10月には、ビジネスデータ分析支援システム「Knowledge Probe20」に実装しています。(図2)


図2: KIBITによるハイライト機能
ハイライトされた箇所が提示されることにより、一定量の文章の中で、KIBITがどの文を重要と判定しているかが「見える化」されています。利用者は、上記箇所を見ることにより、「見つけたいもの」「欲しい結果」に対する説明性や納得度を素早く確認することができます。
ここで改めて、KIBITやConcept Encoderの言語解析プロセスを解説し、どのように「見える化」を行っているかを見てみましょう。まずKIBITを不正調査に使う場合で説明します。今回の調査は「談合」です。社員が日々やり取りしている膨大なメールの中から、談合を行う可能性があるものをAIで探します。
まず、KIBITに学習させるためのメールデータを用意します。談合を行うため、飲み会に誘う「見つけたい」メールと、問題のない普通の飲み会の「見つけなくて良い」メールの2種類です。そして、データをKIBITに入れて、メールの文章を「形態素」に分けます。形態素は文章の中で意味を持つ言語の最小単位で、形態素に分けるプロセスは言語解析の始まりとなります。
同時に、用意したデータが「見つけたい」メールか「見つけなくて良い」メールか、という情報もKIBITに学習させます(図3)。談合に繋がる「見つけたい」メールは、企業が持つ過去のメールやFRONTEOで蓄積したデータを使用できます。
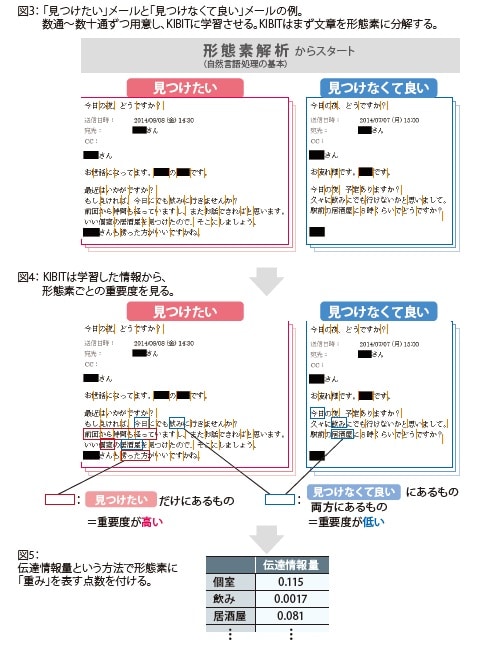
それぞれのメールから学習
KIBITは伝達情報量という方法で用いて、メールで与えられた形態素のうち、「見つけたい」メールのみに含まれているものを「重要度が高い」と見なし 、「見つけなくて良い」と両方にあるものを「重要度が低い」と見なします(図4)。
そして学習したメールの形態素の出現頻度と合わせて計算し、0から1点の間で「重み」を表す点数をつけていきます。この例では「見つけたい」メールだけにある「個室」という形態素は点数が高くなり、重要な成分と言えます。一方、「見つけたい」「見つけなくて良い」の両方にある「飲み」や「居酒屋」は点数が低く、特に出現頻度が多い「飲み」は点数が低くなっています(図5)。
次に文章に含まれる形態素の重要度の「成分」と「量」を学習したKIBITを使って、調査対象となる社員のメールを解析します。通常は数千から数万通のメールを調査することがありますが、イメージとして、26通のメール、合計100個の形態素が分布する解析結果をグラフで表してみました。
「見つけたい」だけにある形態素は、先程の表の「個室」のように高めの点数が付き、グラフ上では長くなります。一方、「見つけなくて良い」にある形態素、また両方にある形態素は、「飲み」のように低い点数がつき、グラフ上で短くなります(図6)。
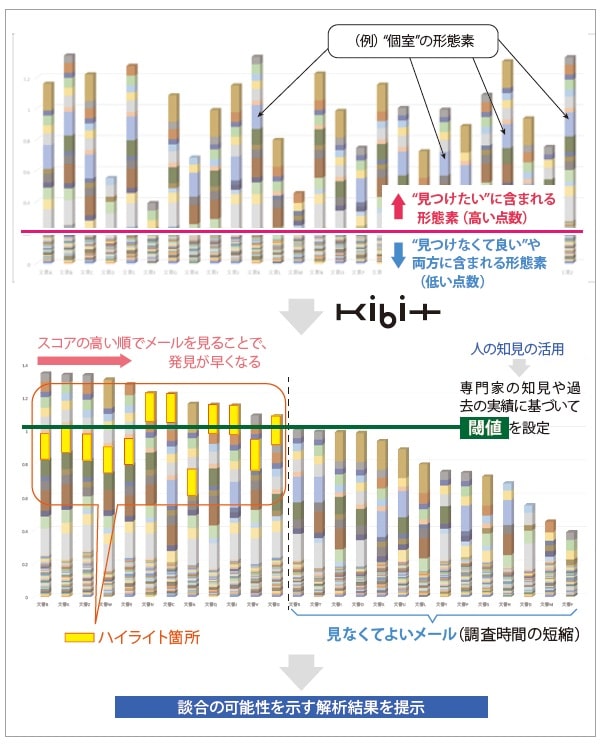

このようにメール1通1通をスコア化することで、順番に並び変えることが容易になります。スコアが高い方が談合の可能性が高いため、順番に見る方がランダムにメールを見ていくよりもずっと早く、証拠となるメールが発見しやすくなります。また、専門家の 知見や経験に基づいて、「あるスコアよりも低いメールは見なくても良い」といった人の判断を加えて、閾値を設定することで、調査時間を大幅に短縮することもできます。
KIBITは、まるで料理の材料を示すように文章の成分を明らかにし、点数が高い形態素を含む一文を重要箇所としてハイライトすることで「見える化」の実現と調査すべきメールを人に提示することができます。




{kind=link}
{kind=link}
{kind=link}