
2025年07月30日
2020年04月10日配信

「人工知能を使う意味って?」「AIを使った業務改善って、どうすればよい?」。人工知能の導入を検討する際に、多くの人がこのようなことを考えると思います。会社で起きている問題や、業務上の課題がはっきりとしていれば、プロセスを見直し、方法を考え、人工知能が適しているかどうか試すことができます。しかし、これまで問題意識を持たずに続けてきた業務を新たな視点で捉え直すのは、なかなか難しいでしょう。今回は、企業に日々寄せられる「お客様の声」という、誰もがイメージしやすい情報に自然言語処理を行うFRONTEOの人工知能エンジン「KIBIT(キビット)」を使うことで、何がどう変わるかを見て、人工知能を使いこなす方法を考えてみましょう。
自社の商品やサービス、社員の行動に対して寄せられるクレームや感謝の声、商品や店舗への感想といったお客様の声やお客様の反応は貴重なデータです。「お客様の声は宝の山である」とはよく言われますが、あなたの周りの会社はどうでしょう?有効活用できている企業は果たしてどれ位いるでしょうか? FRONTEOには、少なくない数の企業から「記録はあるのに多すぎて内容を把握できない」「どうやって振り分ければよいのか」と言った相談が寄せられています。いくら沢山の「声」を集めても、正しく分類し、正しい対応ができなければ、全く役に立たない、というのは容易に想像できると思います。宝の山もずっと山のままなら、ただのデータの塊で、必要な部署に必要な声が届いてこそ、商品開発や店舗オペレーションの改善、危機への対応などの「センサー」として活かすことができます。
では、KIBITを使って、どのように「声」を「宝の山」に変えることができるのでしょうか?(図1) 図1. KIBITが解決できる課題
図1. KIBITが解決できる課題
図1で見られるように、最も分かりやすい優れた点は、高速な処理能力です。ある金融関連企業のコールセンターには1日あたり7,000件、1ヶ月だと20万件もの問い合わせやお客様の声が寄せられており、あるECサイトでは、1日あたり5~60件、1ヶ月で2,000件もの書き込みやSNSでの投稿があります。このような企業でクレーム対応を行う場合、寄せられた問い合わせやご意見・ご感想、SNSへの書き込み・投稿の内容を全て確認し、対応するのは労力がかかり過ぎて、実質的には不可能です。
しかし、「KIBIT」であれば、高速な解析ができるため、1件あたりの文章の量にもよりますが、数千件のデータを数時間で解析し、振り分けることが可能です。従来だと、人が見られる範囲で確認する「サンプルチェック」しかできなかったのが、KIBITを使うことで、網羅性を高めた「全件チェック」を行うことができ、偶然に頼ったり、漏れたり、見逃したりする不確実さを減らせます。さらに、その記録を「見つけたい内容を表している可能性が高い順番」に並び替えることができ、効率良くチェックが行えます(図2)。これは、KIBITに学習させる際に、「見つけたいもの」を教えるだけでなく、「見つけなくてよいもの」も同時に教えることで、探している文章の特徴をあぶり出し、精度を高めることができるので、大きな特長となっています。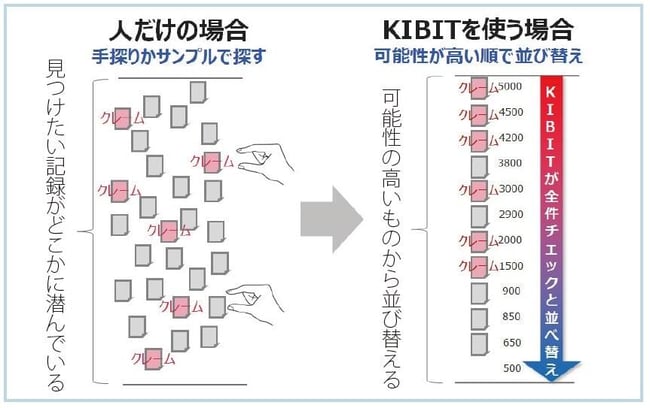
図2. KIBITなら処理が速いうえに、スコアリングで順番が付けられる
「お客様の声」は、問い合わせ、苦情、感謝、意見、要望など様々なものが寄せられます。その中からネガティブ(クレーム)か、ポジティブ(感謝の声)かを分類し、適切な部署に届けるにはどうすればよいでしょう?一番簡単な方法として真っ先に思い浮かぶのは、「キーワード検索」による振り分けではないでしょうか?データ化された「お客様の声」に、自分が見つけたい単語を入力すれば、その単語を含む文章がヒットします。しかし、上記(図3)のように、感謝の声もクレームも同じ単語を使っているケースがあります。この場合、結局は人が見直さないと正しく分類できません。 図3. 同じ単語を使っていても、内容は全く逆
図3. 同じ単語を使っていても、内容は全く逆
また、キーワード検索では、色々なクレームに繋がる単語を見つけだそうとして、キーワードを増やしていくと膨大な数となってしまいます。さらに“甘い”」という言葉は、良い意味でしょうか?悪い意味でしょうか?どちらの使い方もあるでしょう。こういった言葉の選び方や使い方の揺らぎ、多義性(複数の意味で用いられること)、誤った表現などは、人間が普段使う自然文をコンピュータで処理する「自然言語処理」を行う際の重要なポイントとなっています。また、人の判断に影響する認知バイアスも要注意です。コールセンターにかかってきた電話のうち、クレームだと思うものを人が記録し、フラグ(振り分けのための目印)を付ける作業を行った場合、クレームかどうかの判断にブレが生じたり、間違ったりすること(誤フラグ)があり、そのまま放置したことで、望んだ結果が得られないリスクが発生するかもしれません。
例えば、あるECサイトで、お客様が操作ミスをしている間に買いたかった品物が売り切れてしまい、コールセンターに苦情の電話がかかってきたとします。オペレーターは「お客様の操作ミスだから、これは苦情として報告しない」と判断するかもしれません。しかし、ECサイトの責任者にとっては、操作ミスが起こるのはサイトのUI(ユーザーインターフェイス)に問題があるのかもしれず、苦情を言うような操作ミスがなぜ起きたかの情報が重要になる場合があります。大規模なコールセンターで、多くの人が作業に関われば関わるほど、人によって捉え方が異なるため、いくらマニュアルを作っても、欲しい情報が見落とされる可能性があります。(図4) 図4. 主観や判断のブレで、漏れや間違いが発生する
図4. 主観や判断のブレで、漏れや間違いが発生する
自然言語処理を行うAIでの解析は、テキストデータに変換することで音声データも取り扱うことができます。音声データは文字入力と比べて、記録が容易ですが、一方で大きな課題があります。それは音声認識ソフトウェアなどを使って、音声データからテキストデータに変換する際の誤変換です。音声認識の精度は日々向上していますが、話者の性別、年齢、方言や癖など発話の個性や身体の特徴、記録や通信の環境など、音声認識の精度に影響を与える要因には様々なものがあり、現在の音声認識の認識率は、90%前後と言われています。では、実際に音声をテキストにした場合、どの程度の誤変換があるのでしょうか?
図5 は、金融取引の約2分程度のやり取りです。もし、解析の前に全ての誤変換を人間が目で見て修正する必要があるとしたら、その作業に膨大な時間がかかってしまい、現実的でありません。KIBITの場合、誤変換は誤変換のままで、解析をすることが可能です。ある実験では、音声認識の誤変換を修正した場合と、あえて修正せず誤変換のままで解析を行った場合の2つを比較してみました。そうすると、“変換ミスを含んだまま解析しても、精度は下がらない”という結果が出ました。
KIBITは、単語をキーワードとして探したり、辞書のように登録された言葉の意味を比較して、解析結果を出すのではなく、文章全体の構成から特徴を掴み、類似性を判別します。この実験結果は後述するKIBITの強みがあらわれていると言えます。 図5. 金融取引での音声認識の例
図5. 金融取引での音声認識の例
お客様の声や反応には、以下のようなものがあります。
・ コールセンター/コンタクトセンターでのお客様からのインバウンドコール(受電)、お客様へのアウトバウンドコール(架電)
・ 店舗でのアンケート
・ お客様から店員、社員への声掛けやメール
・ ECサイト等でのレビュー
・ 企業サイトへの問い合わせや書き込み
・ SNSなどでの書き込み
「数値」で表せるものが定量データ、表せないものが定性データです。
定量データの場合、一定の数値より上か下かで状態を判断したり、変化を客観的に見ることができますが、定性データは人の主観によって判断や解釈が変わり、扱いが難しいとされます。
FRONTEOのAIエンジンKIBITは定性データの代表である言葉を一定の尺度で点数化(スコアリング)し、定量的に評価することができます。





